 Geschichten erzählen mit modernen Webtechniken
Geschichten erzählen mit modernen WebtechnikenMit modernen Webtechniken lassen sich beeindruckende multimediale Präsentationen erstellen. Aus Text, Bildern, Daten, Audio- und Video-Elementen entstehen so spannende Geschichten und Welten, die Leser interaktiv entdecken können. Die grundlegenden Techniken eignen sich auch für kleinere Projekte.
Am Anfang bestand das Web aus wenig ansehnlichen Texten, die auf andere Texte verwiesen. Seit der ersten Stunde wurde versucht, Webseiten medial anzureichern und interaktiver zu gestalten. Nach fast zwanzig Jahren Web-Geschichte ist es endlich möglich, beeindruckende Webseiten ohne Plugins zu entwickeln. Heutzutage stehen dafür leistungsfähige Webstandards und Browser zur Verfügung.
Zwar gibt es schon länger künstlerische Arbeiten und technische Demos, die Text, Grafik, Video und Audio geschickt kombinieren. Doch anspruchsvolle Webpräsentationen, die eine zusammenhängende Geschichte erzählen, sind etwas Neues. Das interaktive Geschichtenerzählen – Interactive Storytelling – ist im letzten Jahr vor allem durch Feature-Artikel und Reportagen im Online-Journalismus bekannt geworden, aber auch durch Produktpräsentationen. Diese Geschichten wollen informieren, unterhalten, aufrütteln oder schlicht verkaufen. Dabei sprechen sie die Neugier, den Spieltrieb und den Sinn für Ästhetik an.
Beispiele
Fünf Beispiele sollen die konzeptionellen und technischen Aspekte von Interactive Storytelling demonstrieren:
Snow Fall – The Avalanche at Tunnel Creek, Ende 2012
»Snow Fall« ist das bekannteste Beispiel. Die aufwändige Reportage der New York Times erzählt die Geschichte von 16 Freeskiiern, die in ein Lawinenunglück im Nordwesten der USA verwickelt waren. Der Text ist verwoben mit Illustrationen, Interviews, Steckbriefen und Fotogalerien.
Firestorm – The story of the bushfire at Dunalley, Mai 2013
Ebenfalls mit einer Naturkatastrophe beschäftigt sich »Firestorm«, eine Reportage der britischen Zeitung »The Guardian« über eine tasmanische Familie, die nur knapp einen verherrenden Buschbrand überlebt. Die Präsentation besteht aus mehreren Kapiteln, die in Screens aufgeteilt sind. Darin werden Text, Interviews, Naturaufnahmen, Fotos und Sounds gemischt.
Greenpeace: Into the Artic, seit März 2013
Die Greenpeace-Kampagne gegen Ölförderung und Industriefischerei in der Arktis ist im Stil einer Wissensdatenbank aufgebaut. Im Zentrum steht eine Karte, auf der Pfade, Standorte und Ereignisse verzeichnet sind, die mit Statusmeldungen und Artikeln verknüpft sind. Eine Geschichte ist die Reise des Greenpeace-Schiffs »Arctic Sunrise«, welches Ölbohrinseln ansteuerte. Die Medien berichteten jüngst über die Aktion, nachdem die russische Küstenwache das Schiff enterte und die Aktivisten festnahm.
National Geographic: The Serengeti Lion, August 2013
Das für spektakuläre Naturfotografie bekannte Magazin »National Geographic« liefert eine interaktive Tierdokumentation mit bildschirmfüllenden Foto- und Videoaufnahmen von Löwen im Serengeti-Nationalpark. Die Präsentation besteht aus 24 Galerien, die in keiner festen Reihenfolge stehen. Die Aufnahmen sind mit Originalgeräuschen unterlegt und werden durch zuschaltbare Audio-Kommentare und Beschriftungen ergänzt.
The Dangers of Fracking, 2012
Die kompakte Webseite der Interaktions-Designerin Linda Dong visualisiert die Funktionsweise der umstrittenen Ölabbau-Technik und zeigt deren Risiken auf. Geschickt wird das vertikale Scrolling eingesetzt, um die Geschichte fortzuerzählen.
Was ist das Neue an Interactive Storytelling?
Verschiedene Autoren sind sich einige, dass Interactive Storytelling im Web nichts fundamental Neues darstellt. Vielmehr handelt es sich um eine gekonnte und stimmige Kombination bekannter Elemente. Mit HTML5-Video und -Audio, Visualisierungstechniken wie Canvas und SVG sowie CSS-Animationen ist eine nahtlose Integration der verschiedenen Medien möglich. Mit JavaScript werden die Elemente zu einer interaktiven Präsentation verschmolzen.
Die gezeigten Beispiele sind interdisziplinäre Arbeiten. Interactive Storytelling vereint Recherche, journalistisches Schreiben, Fotografie, Filmproduktion – klassische journalistische und publizistische Arbeiten – mit Design und Programmierung fürs Web. Damit das Resultat in verschiedener Hinsicht überzeugt, sind gleichsam interdisziplinäre Teams nötig.
Nach dem phänomenalen Erfolg von »Snow Fall« und ähnlichen Veröffentlichungen wurde heiß diskutiert, ob dies nun die ZukunftdesJournalismus sei. Die meisten Kommentare sind skeptisch: Wenige zeitaufwändige Multimedia-Features sind nicht in der Lage, genügend Werbeeinnahmen zu erzielen und Leser zu binden.
Es steht jedoch außer Frage, dass Interactive Storytelling das Web bereichern kann. Die gezeigten Präsentationen wirken auf verschiedenen Ebenen: Sie erzählen spannende Geschichten, machen Fakten zugänglichen, vermitteln Wissen, wecken Emotionen und appellieren an den Leser.
Typische Elemente
So zahlreichdie Beispiele auch sind, es sind häufige Gemeinsamkeiten festzustellen. Die meisten Geschichten nutzen ein raumgreifendes, minimalistisches Design ohne Schmuckelemente. Anstatt die Inhalte in ein klassisches Layout mit Header, Footer und Seitenleisten zu zwängen, nehmen sie den gesamten Bildschirm ein und sprechen für sich. Dahinter steht ein Design-Trend, der Zurückhaltung und Reduktion aufs Wesentliche beinhaltet.
Auch wenn Text nur noch ein erzählerisches Element unter vielen ist ist, so gewinnt die Typographie an gestalterischer Bedeutung. Die verbleibende Schrift ist von Wichtigkeit und Aussagekraft, daher wird mit großen, fast bildschirmfüllenden Überschriften und Teaser-Texten sowie vergleichsweise großem Fließtext gearbeitet.
Das vertikale Scrolling ist eine bekannte Möglichkeit, um weitere Inhalte einer Webseite zu erreichen. Daher nutzen viele Präsentationen die Scrollfunktion, um zwischen den Kapiteln und Abschnitten zu navigieren. Manche Präsentationen wie das Fracking-Beispiel koppeln die Scrollbewegung gar an das Objekt der Erzählung, das vom Nutzer fortbewegt wird und damit die Geschichte vorantreibt.
Als visuelle Medien finden sich hochauflösende Fotos, Infografiken, Datenvisualisierung und Karten. Videos werden für informative Animationen, für Interviews oder zur Erzeugung von Stimmung genutzt. Tonaufnahmen sind zumeist O-Töne aus Interviews oder Hintergrundgeräusche zur Erzeugung von Stimmung.
Die Präsentationen entfalten ihr Potenzial dann, wenn sie Text, Bild und Ton miteinander sowie mit Zeit, Ort und Person verknüpfen. Beim Lesen des Textes wird beispielsweise das Beschriebene in einem Schaubild illustriert, ein Steckbrief des Protagonisten verlinkt oder der Ort des Ereignisses auf einer Karte fokussiert.
Was heißt Interaktivität?
Wenn hier von interaktiven Geschichten die Rede ist, so stellt sich die Frage, was das Erzählen interaktiv macht. Wie viel Entscheidungsfreiheit hat der Leser wirklich?
Zumeist bildet das Gerüst ein fortlaufender Text, der eine Geschichte mit klassischem Spannungsbogen erzählt. Dieser Text will linear von vorne bis hinten gelesen werden, hat allerdings Marginalien mit Zusatzinfos und eingebetteten Medien, die der Leser auch überspringen kann. Lorenz Matzat spricht deshalb von »Pseudo-Interaktivität«: »Man könnte bei vielen neueren ›interaktiven‹ Formaten schlicht von Slideshow 2.0 sprechen: Letztlich besteht die Interaktionen mit ihnen daraus, Abzweigungen zu nehmen, um die Erzählrichtung zu ändern oder in ein Thema tiefer einzusteigen.«
Doch es gibt auch Gegenbeispiele. Die Löwen-Aufnahmen von National Geographic haben keine lineare Struktur. Der Leser kann frei durch einen großen Fundus an verschiedenen Medien navigieren. Auch die Greenpeace-Publikation ist eher eine Wissendatenbank, die Ereignisse, Orte und Hintergrundinformationen verknüpft und zum explorativen Lesen einlädt.
Das erinnert an die ursprüngliche Idee des Hypertextes: »Jeder Leser komponiert den Gegenstand seiner Lektüre durch aktive Selektion der vorgegebenen Links. (…) Lesen ist nicht länger ein passiver Vorgang der Rezeption, sondern wird zu einem Prozeß der kreativen Interaktion zwischen Leser, Autor und Text.« (Hypertextualität im World Wide Web, Mike Sandbothe, 1996).
Storytelling: Klein anfangen
Die vorgestellten Beispiele sind sehr umfangreich und ausgereift, sollen aber nicht vom eigenen Experimentieren abhalten. Jedem Webentwickler ist es möglich, Geschichten zu erzählen. Ihr könnt einfach klein anfangen:
Zunächst einmal sucht euch Mitstreiter, deren Fähigkeiten sich ergänzen. Stellt ein Team zusammen, das verschiedene Bereiche wie Entwicklung, Gestaltung, Schreiben und Medienproduktion abdeckt.
Am Anfang der inhaltlichen Arbeit steht die Grundidee bzw. ein Thema. Der Hauptstrang und eventuelle Nebenstränge der Erzählung werden identifiziert. Welche Erzählperspektive(n) werden eingenommen? Welche Orte, Personen, Ereignisse und Daten kommen vor? Gibt es eine lineare Kapitelstruktur oder eine nichtlineare Navigation? Gibt es eine klare Absicht, gar einen Appell an den Leser? Wodurch wird eine Stimmung erzeugt, Lebendigkeit erreicht? Wie werden die Leser eingebunden?
Auf die Konzeptionsphase folgt das Sammeln von Texten, Bildern, Videos, Tönen, Gegenständen usw. Dabei können auch vorgefertigte freie Fotos, GIF-Animationen, YouTube-Videos, Vine- und Instagram-Bilder, Karten- und Kommentar-Widgets eingebunden werden.
Um die Grundstruktur der Erzählung zu skizzieren, eignet sich das aus der Filmproduktion bekannte Storyboard, auf dem die Materialien arrangiert und die Interaktionen angedeutet werden. Aus dem Webdesign sind Wireframes als Entwurfswerkzeug bekannt.
Technische Umsetzung
Für eine gelungenes Interactive Storytelling müssen verschiedene Techniken zusammengeführt werden. Die detaillierte Umsetzung des Beispiels »Snow Fall« erörtern der Artikel Snow Fall Breakdown und das Interview How we made Snow Fall.
Am Anfang steht ein HTML-Dokument, das strukturierten Text enthält, andere Medien einbettet sowie die Präsentation in Gang setzt. Neben der HTML5-Textstrukturierung können die video- und audio-Elemente zur direkten Einbettung von Video- und Audiodaten verwendet werden. Falls ein komplexer Player zur Steuerung nötig ist oder ein Flash-Fallback gewünscht ist, so hilft die Übersicht HTML5 Video/Audio Player bei der Auswahl.
Mittels CSS wird die Typographie und ein anpassungsfähiges Layout umgesetzt. Dafür können klassische Float-Layouts mit Media-Queries, aber auch das Flexbox zum Einsatz kommen. Für flüssige Übergänge und Bewegung sorgen einfache CSS3-Transitions sowie leistungsfähige Keyframe-Animationen, die von neueren Browsern hardwarebeschleunigt dargestellt werden. Bei der Erstellung von Keyframe-Animationen helfen die (kostenpflichtigen) Programme Adobe Edge Animator und Sencha Animator.
In den meisten Fällen ist JavaScript der Kleber, der alle Teile zusammenfügt und interaktiv werden lässt. Mit JavaScript wird zwischen den Kapiteln navigiert, Animationen werden angestoßen, Medien werden geladen und gesteuert. Die DOM-Bibliothek jQuery stellt eine gute Ausgangsbasis dar. Es ist ratsam, die Storyboard-Struktur in JavaScript-Code umsetzen: Der Code wird in Screens und Übergängen (Transitions) zwischen den Screens aufgeteilt. Darüber steht eine Logik, die die Screens verwaltet sowie den Initialisierungscode der Transitions und der Screens aufruft.
Für diese Zwecke kommen verschiedene jQuery-Plugins in Frage. Wenn die Präsentation auf das Scrolling reagieren soll, so eignen sich die Events scroll sowie mousewheel. jquery.inview feuert einen Event, wenn sich ein Element im Viewport befindet. Damit können automatisch Medien geladen und gegebenenfalls abgespielt werden.
Empfehlungen
Was macht das interaktive Geschichtenerzählen im Web erfolgreich?
Im Gegensatz zu vielen konventionellen Webseiten sollten Geschichten dezent statt aufdringlich sein, indem sie sich auf ihre Stärken fokussieren. Sie sollten die Neugier der Leser wecken und Entscheidungen ermöglichen. Dabei hilft eine klare Grundstruktur, z.B. ein fortlaufender Text. Gleichzeitig sollte es Seitenpfade geben, auf denen es viel zu entdecken gibt.
Zurückhaltung ist auch bei visuellen Effekten und Animationen angesagt. Insbesondere Scrolling- und Parallaxen-Effekte sind im heutigen Web allgegenwärtig, sodass Leser ihnen schon überdrüssig sind. Effekte sollten mit Bedacht als bedeutungsvolles Erzählmittel eingesetzt werden. Scrolling zum Beispiel ist eine Möglichkeit, um von einem Element der Geschichte zum nächsten zu springen. Es sollte nicht verwendet werden, um sämtliche Seitenelemente einfliegen zu lassen. Bewegung zieht Aufmerksamkeit auf sich, kann Kontraste erzeugen und Übergänge vermitteln.
Das Schreiben von Geschichten im Web ist wie gesagt eine Teamarbeit, die ein gemeinsames Verständnis erfordert. Alle Beteiligten können ihre Perspektive auf die Geschichte einfließen lassen.
Mathias Schäfer Websites abdichten
Websites abdichten

 Navigation im Responsive Design – Teil I
Navigation im Responsive Design – Teil I




 Navigation im responsive Design – Teil II
Navigation im responsive Design – Teil II


 Contenterstellung für SEO
Contenterstellung für SEO
 Kolumne
Kolumne
 Einstieg in ARIA 1.0 – Teil I
Einstieg in ARIA 1.0 – Teil I Einstieg in ARIA 1.0 – Teil II
Einstieg in ARIA 1.0 – Teil II

 CSS-Präprozessoren
CSS-Präprozessoren HTML5
HTML5


 SASS für ältere IE nutzen
SASS für ältere IE nutzen, 1798") Kolumne
Kolumne Usability Engineering: Arbeiten mit Nutzungsanforderungen
Usability Engineering: Arbeiten mit Nutzungsanforderungen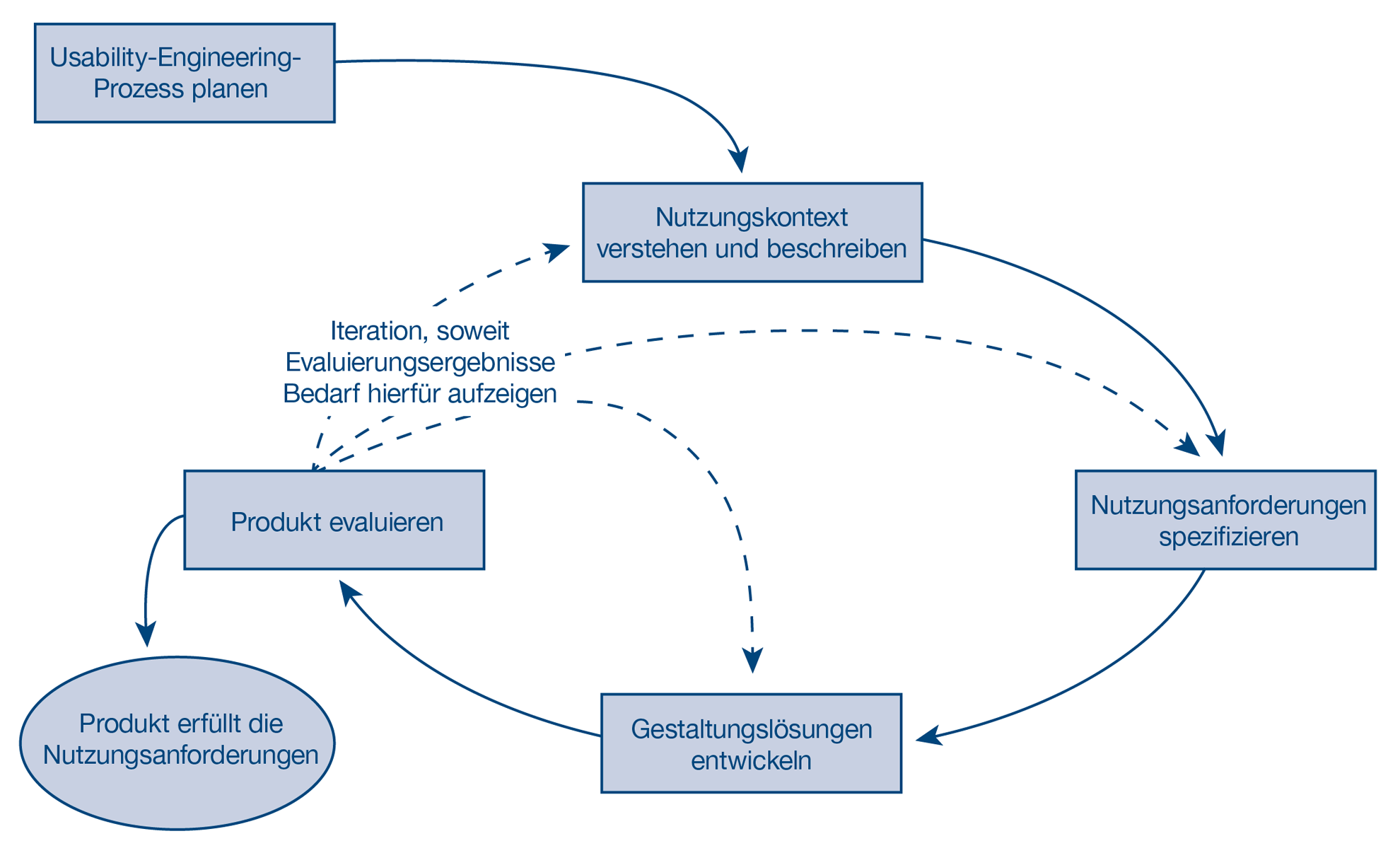
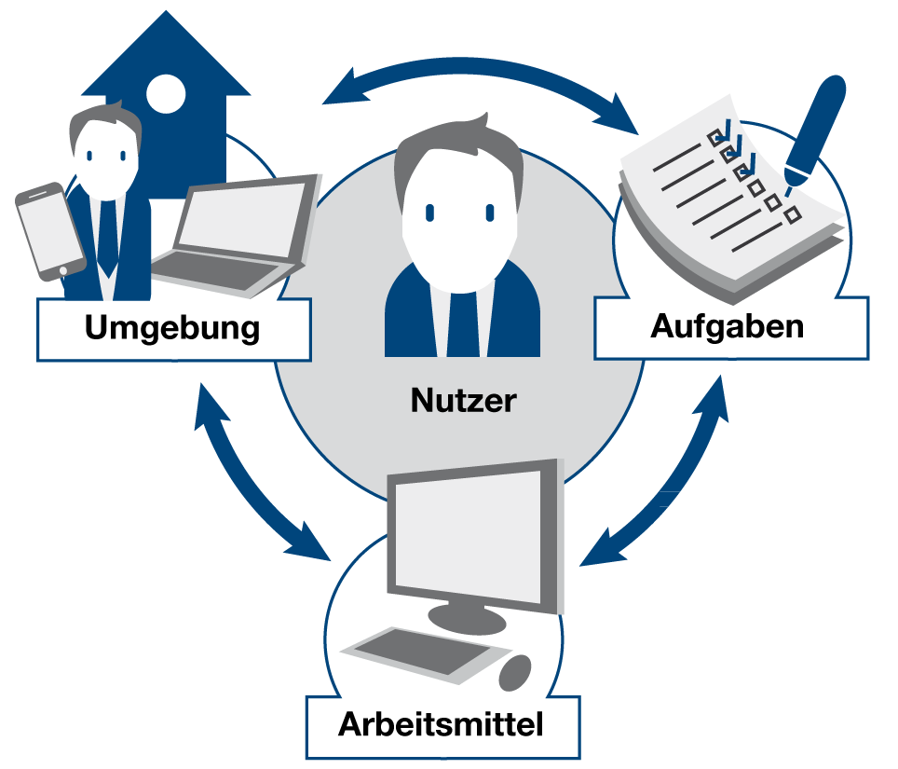
 Usability Engineering: Benutzerzentrierte Analysen in der Praxis
Usability Engineering: Benutzerzentrierte Analysen in der Praxis
 Syntax-Highlighter
Syntax-Highlighter


 Pointer-Events für Maus, Stylus und Touchscreen
Pointer-Events für Maus, Stylus und Touchscreen




 Was heutzutage alles in den Head muss – und was nicht
Was heutzutage alles in den Head muss – und was nicht Was heutzutage alles in den head muss – Teil II
Was heutzutage alles in den head muss – Teil II